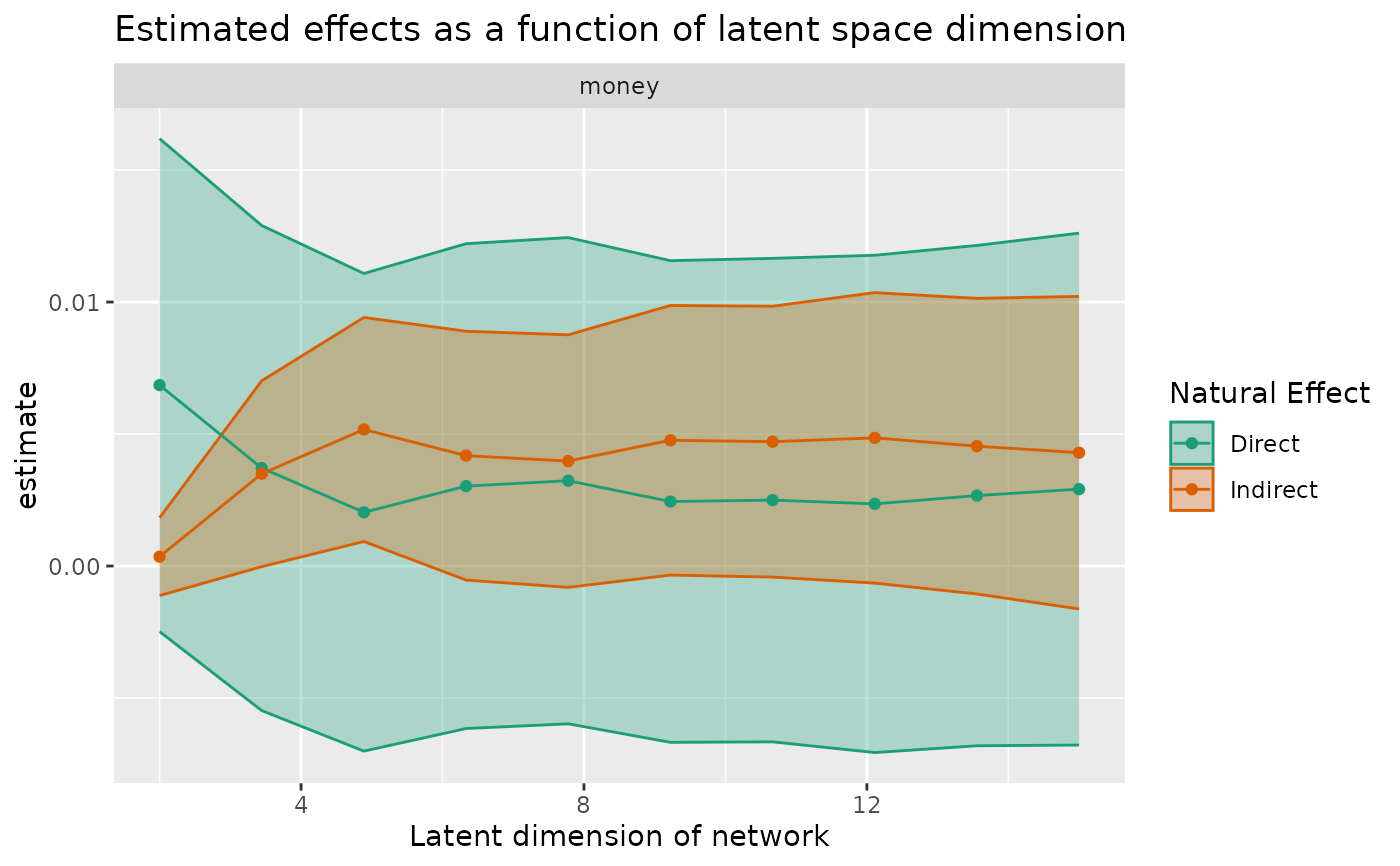
Estimate mediated effects for a variety of embedding dimensions
Source:R/mediation.R
sensitivity_curve_long.RdEstimate mediated effects for a variety of embedding dimensions
Usage
sensitivity_curve_long(
graph,
formula,
max_rank,
...,
ranks_to_consider = 10,
coembedding = c("U", "V"),
node_data = NULL
)Arguments
- graph
A
tidygraph::tbl_graph()object.- formula
Details about the nodal design matrix. Of the form outcome ~ nodal_formula. For now, no interactions or fancy stuff are allowed in the formula.
- max_rank
Maximum rank to consider (integer).
- ...
Arguments passed on to
estimatr::lm_robustdataA
data.frameweightsthe bare (unquoted) names of the weights variable in the supplied data.
subsetAn optional bare (unquoted) expression specifying a subset of observations to be used.
clustersAn optional bare (unquoted) name of the variable that corresponds to the clusters in the data.
fixed_effectsAn optional right-sided formula containing the fixed effects that will be projected out of the data, such as
~ blockID. Do not pass multiple-fixed effects with intersecting groups. Speed gains are greatest for variables with large numbers of groups and when using "HC1" or "stata" standard errors. See 'Details'.se_typeThe sort of standard error sought. If
clustersis not specified the options are "HC0", "HC1" (or "stata", the equivalent), "HC2" (default), "HC3", or "classical". Ifclustersis specified the options are "CR0", "CR2" (default), or "stata". Can also specify "none", which may speed up estimation of the coefficients.cilogical. Whether to compute and return p-values and confidence intervals, TRUE by default.
alphaThe significance level, 0.05 by default.
return_vcovlogical. Whether to return the variance-covariance matrix for later usage, TRUE by default.
try_choleskylogical. Whether to try using a Cholesky decomposition to solve least squares instead of a QR decomposition, FALSE by default. Using a Cholesky decomposition may result in speed gains, but should only be used if users are sure their model is full-rank (i.e., there is no perfect multi-collinearity)
- ranks_to_consider
How many distinct ranks to consider (integer). Optional, defaults to 10.
- coembedding
TODO
- node_data
TODO
Value
A rank_sensitivity_curve object, which is a subclass of a
tibble::tibble().
Examples
library(tidygraph)
library(dplyr)
data(smoking, package = "latentnetmediate")
# example with fully observed node data
rank_curve <- smoking |>
mutate(
smokes_int = as.integer(smokes) - 1
) |>
sensitivity_curve(
smokes_int ~ sex,
max_rank = 25,
ranks_to_consider = 24,
se_type = "stata"
)
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Warning: In lm.fit(x, y, offset = offset, singular.ok = singular.ok, ...) :
#> extra argument ‘se_type’ will be disregarded
#> Error in sensitivity_curve(mutate(smoking, smokes_int = as.integer(smokes) - 1), smokes_int ~ sex, max_rank = 25, ranks_to_consider = 24, se_type = "stata"): Arguments in `...` must be used.
#> ✖ Problematic argument:
#> • se_type = "stata"
#> ℹ Did you misspell an argument name?
rank_curve
#> Error in eval(expr, envir, enclos): object 'rank_curve' not found
plot(rank_curve)
#> Error in eval(expr, envir, enclos): object 'rank_curve' not found
# example with some missing node data. in this case, all edges are
# used to estimate embeddings, but once the embeddings are in hand,
# the regression only considers complete cases
data(glasgow, package = "latentnetmediate")
glasgow1 <- glasgow[[1]] |>
activate(nodes) |>
filter(selection129) |>
mutate(
smokes_dimaria = as.numeric(tobacco_int > 1)
) |>
activate(edges) |>
filter(friendship != "Structurally missing") |>
activate(nodes)
# verify that there is some missing data, in this case treatment indicators
glasgow1 |>
as_tibble() |>
count(is.na(money))
#> # A tibble: 2 × 2
#> `is.na(money)` n
#> <lgl> <int>
#> 1 FALSE 126
#> 2 TRUE 3
glasgow1 |>
sensitivity_curve(smokes_dimaria ~ money, max_rank = 15, coembedding = "V") |>
plot()